Return to All Blogs
What Is AI Code Review? A Complete Guide
Understand AI code review, its advantages, and how it helps improve code quality and reduce errors in software development.


AI code review uses machine-learning and generative AI tools to scan source code for bugs, security risks, performance bottlenecks, and style violations : delivering instant, consistent feedback inside the developer's workflow. Adopted alongside human reviewers, it cuts review time, standardizes quality across teams, and integrates directly into CI/CD pipelines.
This guide covers the process, benefits, top tools, platform integrations, and limitations of AI code review : so you can decide where it fits in your stack and how to get started without disrupting your existing workflow.
What Is AI Code Review?
AI code review uses artificial intelligence algorithms to analyze source code for potential issues. These tools automatically detect bugs, security vulnerabilities, performance bottlenecks, and deviations from coding standards. They provide instant feedback directly within the developer's workflow.
AI reviews code much faster than a human can. It operates with high efficiency and without the inherent biases that can affect manual reviews. This leads to more consistent and objective feedback, helping to standardize code quality across large teams. A proper AI code review process is a cornerstone of modern development.
Types of AI Used in Code Review
The technology behind these tools varies, but it generally falls into a few key categories.
Predictive code review: This refers to tools that use machine learning models trained on vast datasets of open-source code. They learn patterns of common errors and best practices to provide intelligent suggestions.
Code review with generative AI: This is a more advanced form. Generative AI models, like those powering GitHub Copilot or Claude AI, do not just find issues. They can also rewrite and suggest complete, production-ready code snippets to fix them.
Automated AI code review: This type focuses on seamless integration into the development pipeline. It automatically triggers reviews on new code commits or pull requests, providing continuous quality assurance without any manual intervention.
How AI Code Review Works
Understanding the mechanics of AI code review helps in appreciating its power. The process is systematic and data-driven.
The Process of AI Code Review
The workflow typically involves three key steps.
Analysis: The AI tool scans the code. It parses the syntax and structure to understand its purpose and logic.
Suggestion: Using its trained models, the AI identifies potential problems. It flags everything from simple style inconsistencies to complex security risks like SQL injection.
Feedback: The tool presents its findings to the developer. This feedback often includes not only a description of the issue but also concrete suggestions for how to fix it, sometimes with code examples.
Role of Machine Learning and Natural Language Processing
Machine Learning (ML) is the engine behind AI code review. These systems train on millions of lines of code from public repositories. This massive dataset allows the AI to learn the nuances of different programming languages and identify what constitutes high-quality, secure code.
Natural Language Processing (NLP) also plays a crucial role. It helps the AI understand the comments and documentation within the code. This provides context, enabling the tool to make more relevant and accurate suggestions.
AI vs. Manual Code Review
Both AI-assisted and traditional human-led reviews have their place in a modern development workflow. Understanding their distinct advantages helps teams create a balanced and effective quality assurance strategy. The second use of the primary keyword, AI code review, emphasizes its role in this comparison.
Feature | AI-Assisted Code Review | Manual Code Review |
Speed | Extremely fast. A review taking a developer hours can be done in minutes (e.g., reducing a 2-hour task to 15 minutes). | Slow; dependent on human availability and focus. |
Accuracy | Highly accurate for known bugs and style issues. | Variable; depends on the reviewer's expertise. |
Consistency | Perfectly consistent; applies the same rules every time. | Inconsistent; subject to human mood, bias, and fatigue. |
Context | Limited understanding of business logic and intent. | Excellent at understanding business context and goals. |
Scope | Best for security, performance, and style checks. | Best for architectural decisions and complex logic validation. |
Scalability | Scales effortlessly across any number of projects. | Difficult to scale; requires more developers. |
Top AI Code Review Tools
The market for AI code review tools is expanding rapidly. Here is a curated list of some of the top solutions available today, each with unique strengths.
Dualite.dev: An AI coding tool that helps developers generate code & write code faster with fewer errors.
Traycer: Focuses on debugging and error tracing in production environments.
GitHub Copilot: Integrated directly into the GitHub ecosystem, it provides code suggestions and can now review pull requests, summarizing changes and flagging issues.
CodeRabbitAI: Specializes in providing line-by-line suggestions on pull requests, acting like a virtual team member.
PullSense: Analyzes developer activity in pull requests to provide metrics and insights for engineering managers.
Codeant AI: A free tool that offers intelligent code completion and review features within the IDE.
Sweep AI: An AI junior developer that helps fix small bugs and implement feature requests.
CodePeer: An advanced static analysis tool for the Ada programming language, designed for high-integrity systems.
PullRequest: Combines automated analysis with a network of on-demand human expert reviewers.
Graphite Reviewer: An AI-powered tool that automates the creation and review of pull requests.
Korbit AI: Provides AI-driven mentorship and feedback for developers, helping them learn best practices.
Cody by Sourcegraph: Understands your entire codebase to answer questions and write code that matches your established style.
Kody: An AI coding assistant focused on helping developers write code faster and with fewer errors.
Claude AI Sonnet: A powerful generative AI model that can be used for sophisticated code analysis and generation tasks.
CloudAEye: An observability platform that uses AI to detect and resolve issues in cloud-native applications.
Sourcery: Refactors code instantly, helping to clean up and improve the quality of an existing codebase.
Greptile: An AI tool that understands entire code repositories to provide context-aware assistance.
Codacy: An automated code analysis platform that checks for quality, security, and style across more than 40 programming languages.
Features to Look for in AI Code Review Tools
When selecting a tool, you should consider several key features.
Accuracy: Does it find meaningful issues without too many false positives?
Speed: How quickly does it provide feedback on your codebase?
Integration: Does it connect with your essential tools like VS Code, GitHub, GitLab, and Bitbucket?
Security Features: Does it specialize in finding security flaws, like the OWASP Top 10?
Language Support: Does it support your team's main programming languages and frameworks?
Free AI Code Review Tools
Adopting new technology does not have to be expensive. Several powerful AI code review tools are available for free, making them accessible to individual developers and small teams.
Top Free AI Code Review Tools
Two excellent examples of free offerings are Codeant AI and Codacy.
Codeant AI: This tool integrates directly into your IDE. It provides smart code completions and on-the-fly analysis to catch errors before they are even committed.
Codacy: Codacy offers a free tier for open-source projects and small teams. It automates code reviews and monitors code quality over time, providing a dashboard with actionable insights.
Pros and Cons of Using Free Tools
Free tools provide a great entry point into the world of AI-assisted development.
Pros:
No Cost: You can start improving your code quality immediately without any financial investment.
Easy Adoption: They are typically simple to set up and start using.
Core Functionality: Most free tools offer the essential features needed for basic code scanning.
Cons:
Limited Features: Advanced features, such as enterprise-grade security scanning or detailed reporting, are often reserved for paid plans.
Usage Caps: There may be limits on the number of users, private repositories, or lines of code you can analyze.
Less Support: Customer support may be limited compared to paid tiers.
How to Get Started with Free Tools
Getting started is usually straightforward. Here is a general guide:
Choose a Tool: Select a tool that supports your programming language and integrates with your version control system.
Sign Up: Create a free account using your GitHub, GitLab, or Bitbucket credentials.
Authorize Access: Grant the tool permission to access your repositories.
Configure Analysis: The tool will typically analyze your default branch automatically. You can then configure it to run on every new pull request.
Review Feedback: View the analysis results on the tool's dashboard or directly in your pull requests as comments.
Automated AI Code Review
Automated AI code review takes the concept a step further by removing the manual trigger from the process. It is about creating a system of continuous, unattended quality checks.
What is Automated AI Code Review?
Automated AI code review refers to systems that are configured to run without human intervention. These tools are integrated directly into a team's continuous integration and continuous delivery (CI/CD) pipeline. Every time a developer pushes new code, the AI review process is automatically initiated.
This ensures that every single line of code is checked against predefined quality and security standards before it can be merged. It acts as an unblinking, vigilant guardian of your codebase.
How Automation Works in AI Code Review
Automation is achieved through webhooks and API integrations. When an event occurs in your Git platform, like the creation of a pull request, a webhook notifies the AI tool. The tool then pulls the relevant code, performs its analysis, and posts the results back to the pull request page.
This seamless integration means developers receive feedback in the same environment where they manage their code. It becomes a natural part of the development workflow rather than an additional, separate step.
Benefits of Automated AI Code Review
Automating this process brings significant advantages.
Increased Speed: Feedback is delivered within minutes of a code push. This accelerates the entire development cycle.
Fewer Human Errors: Automation ensures that no review is ever skipped or rushed. It guarantees 100% coverage.
Continuous Integration: It is a core component of a modern CI/CD pipeline, enabling teams to ship features faster and more reliably. A study from Stanford University in 2025 found that teams using automated AI review tools reduced their code integration time by an average of 30%.
Challenges with Automated AI Code Review
The primary limitation of automated code review is the system's difficulty in understanding complex code and context-specific requirements. An automated tool might not grasp the particular business logic that makes a piece of code correct for your specific application, even if that code violates a general best practice.
For example, imagine a function that applies a 100% discount to a special category of new users for a promotion. An automated reviewer could flag this as a critical bug, identifying a potential for zero revenue because it lacks the context of the marketing campaign's business rule.
This is why a human element often remains essential for final approval, as a person can validate the code against specific business objectives that an automated system might misinterpret.
Code Review with AI: Key Benefits
Integrating AI into your code review process delivers tangible benefits that impact productivity, quality, and your bottom line. An effective strategy for AI code review is a competitive advantage.
1) Efficiency and Speed
AI tools review massive codebases in a fraction of the time it would take a human. According to 2025 research, developers can spend up to 20% of their time on manual code reviews. AI streamlines the code review process, drastically cutting down on engineering overhead and allowing developers to prioritize feature development. Moreover, AI offers comprehensive explanations and visual aids to illustrate your code's architecture.
2) Improved Code Quality
AI is exceptionally good at detecting common bugs, potential security vulnerabilities, and "code smells" (indicators of deeper problems). By catching these issues early, the AI helps maintain a high standard of quality and reduces the long-term technical debt of a project.
3) Reduction of Human Bias
Human reviews can be subjective. Factors like familiarity with the developer or fatigue can influence the feedback. AI eliminates this by applying a consistent and objective set of rules to every piece of code, ensuring fairness and standardization.
4) Cost-Effective and Scalable
An AI tool can serve a team of five or five hundred with the same level of performance. This makes AI code review an incredibly cost-effective solution. It scales to handle large, complex projects without the need to hire more developers specifically for review tasks.
Challenges of AI Code Review
While the benefits are compelling, it is crucial to acknowledge the limitations and challenges associated with AI code review.
1) Missed Context-Specific Issues
AI tools excel at pattern recognition but lack true comprehension. As often noted in developer discussions on platforms like Reddit, an AI might flag perfectly valid code because it doesn't understand the specific business requirement it fulfills. A human reviewer is needed to catch nuances related to the project's unique context.
2) AI’s Limited Understanding of Business Logic
This is a significant challenge. An AI tool cannot validate that the code correctly implements a complex business rule. It can check if the code is well-written, but not if it does the right thing. Research published by ACM in late 2024 indicated that AI tools often struggle to identify errors in business logic without specific, human-provided context.
3) Tool Compatibility and Integration
For an AI tool to be effective, it must integrate smoothly into your existing tech stack. This includes your Integrated Development Environment (IDE), your CI/CD pipeline, and your Git platform (GitHub, GitLab, Bitbucket). Poor integration can create friction and hinder adoption.
4) Legal and Ethical Concerns
The use of AI in code review raises important questions about intellectual property (IP). For instance, the ongoing legal challenges involving GitHub Copilot allege that the service reproduces licensed open-source code without the required attribution, creating potential compliance and ownership disputes.
Separately, regulatory frameworks like the European Union's AI Act are establishing new precedents, which could mandate transparency about machine-generated output. Consequently, teams must carefully examine the licensing terms of their tools and be aware of potential code originality issues to avoid legal risks.
AI Code Review on Popular Platforms
The power of AI code review is most apparent when it is deeply integrated into the platforms developers use every day.
Platform | Native AI Tool(s) | Third-Party Integration | Key Features |
GitHub | GitHub Copilot | Yes (e.g., Codacy, Snyk via Marketplace) | Summarizes changes in pull requests, flags potential issues, and posts feedback as comments. |
GitLab | GitLab Duo | Yes | Provides code suggestions, vulnerability analysis, and integrates into merge request workflows. |
Bitbucket | (Primarily via Marketplace) | Yes (e.g., Codacy, Snyk) | Connects to repositories to provide automated analysis on pull requests within the Atlassian suite. |
Visual Studio Code | (Via Extensions) | Yes (e.g., GitHub Copilot, Sourcery) | Offers real-time, in-editor feedback and code suggestions as the developer types. |
IntelliJ / JetBrains | JetBrains AI Assistant | Yes | Provides in-editor chat, code generation, and analysis integrated with the IDE's inspection tools. |
AWS | Amazon CodeGuru Reviewer | Yes | Uses machine learning to find critical bugs and recommends code quality improvements. |
Azure | (Primarily via Marketplace) | Yes (via Azure DevOps Marketplace) | Adds automated code analysis as a step in CI/CD build and release pipelines. |
AI Code Review on GitHub
GitHub is at the forefront of AI integration with GitHub Copilot. Copilot can now be used in pull requests to automatically summarize changes and flag potential issues. Many other tools from the marketplace, like Codacy and Snyk, also integrate directly into GitHub pull requests.
To set this up, you typically install a GitHub App, grant it repository access, and configure it to run on pull requests. The AI's feedback will then appear as comments directly on the changed files.
AI Code Review on GitLab
GitLab has its own suite of AI-powered features called GitLab Duo. It includes capabilities like Code Suggestions and vulnerability analysis. GitLab also supports integration with third-party AI tools, allowing you to embed automated reviews within its merge request workflow.
AI Code Review on Bitbucket
Bitbucket, part of the Atlassian suite, also supports AI code review through marketplace apps. Tools like Codacy and Snyk can connect to your Bitbucket repositories to provide automated analysis on pull requests, helping teams maintain code quality within the Atlassian ecosystem.
AI Code Review in Visual Studio Code (VSCode)
Many AI tools offer extensions for VSCode, bringing the review process directly into the editor. Extensions like GitHub Copilot, Codeant AI, and Sourcery provide real-time feedback and suggestions as you type, catching errors before they are ever committed.
AI Code Review in IntelliJ IDEA and JetBrains
The JetBrains family of IDEs offers its own AI Assistant. This tool provides in-editor chat, code generation, and analysis. It integrates with the IDE's powerful code inspection capabilities to offer a seamless AI-assisted development experience.
AI Code Review for Azure and AWS
Cloud platforms provide their own native solutions.
AWS offers Amazon CodeGuru Reviewer. It uses machine learning to identify critical issues and hard-to-find bugs in your code and provides recommendations to improve quality.
Azure DevOps integrates with various AI tools through its marketplace. It allows teams to add automated code analysis as a step in their build and release pipelines, ensuring code quality for applications deployed on Azure.
Generative AI and Its Role in Code Review
Generative AI represents the next frontier for AI-assisted development. This technology moves beyond simple analysis to active creation.
What is Generative AI in Code Review?
In the context of code review, generative AI does not just find problems—it actively suggests solutions. It can rewrite entire functions, generate boilerplate code, and create documentation. This technology uses Large Language Models (LLMs) to understand the intent behind code and produce human-like output. The AI code review becomes a creative partnership.
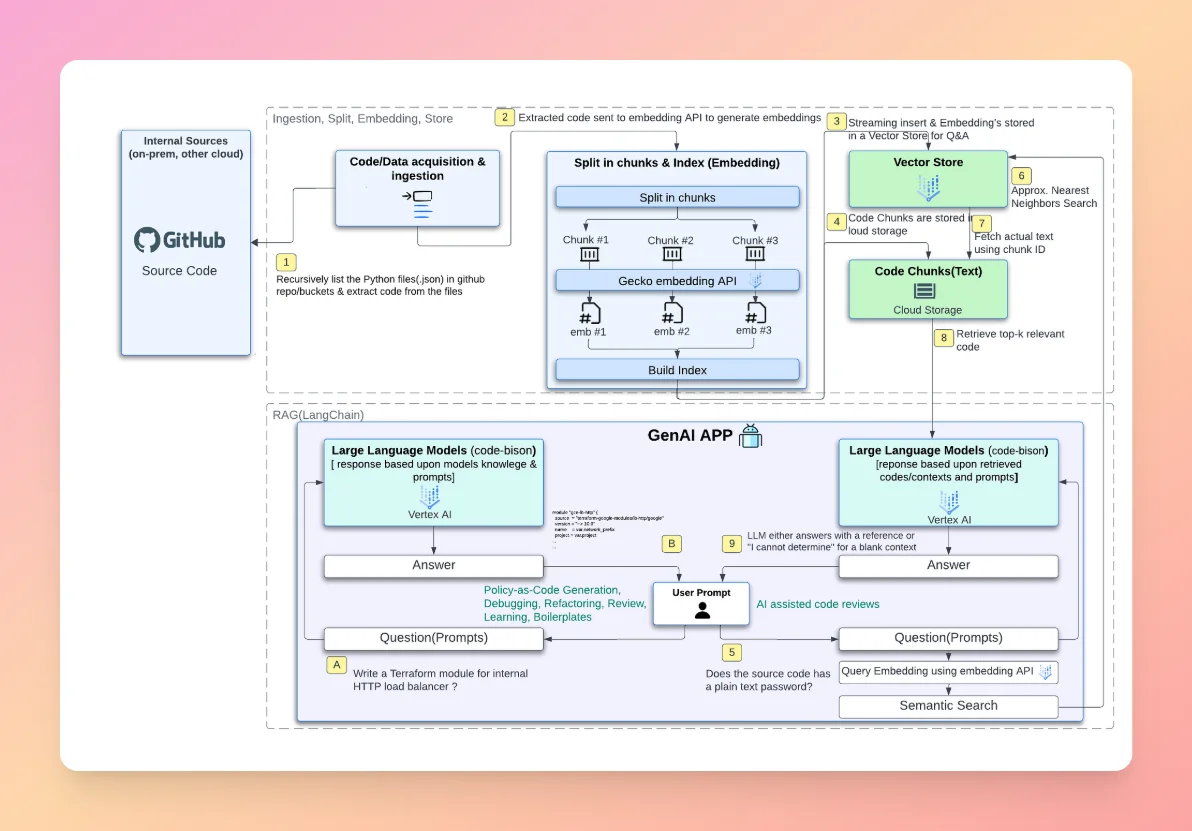
Examples of Generative AI in Code Review
Several tools are leading the way in this area.
GitHub Copilot: Perhaps the most well-known example, Copilot can suggest entire lines or blocks of code based on the current context. Its latest features are expanding into suggesting refactors during the review stage.
Claude AI Sonnet: Anthropic's powerful model can be used to analyze large blocks of code, explain their functionality in plain English, and suggest improvements or optimizations.
Graphite AI: This tool uses generative AI to help automate the entire pull request process, from writing descriptions to suggesting changes.
Limitations of Generative AI in Code Review
The primary challenge for generative AI is its struggle with comprehending complex, large-scale codebase architecture. While it excels at local, line-by-line suggestions, it can sometimes produce code that does not fit well with the broader system design. It may also hallucinate solutions that seem plausible but are functionally incorrect. Human oversight remains critical.
Conclusion
The trajectory of AI code review is clear: it will become more intelligent, more integrated, and more indispensable. We anticipate that future AI will have a deeper understanding of application-specific context and business logic. Gartner projects that by 2026, over 75% of enterprise development teams will rely on AI assistants for code generation or review, solidifying their place in the standard developer toolkit.
Should You Use AI for Code Review?
Yes. The question is no longer if you should use AI for code review, but how. A hybrid approach that combines the speed and consistency of AI with the contextual understanding and wisdom of human reviewers offers the most powerful solution. Let AI handle the routine checks so your team can focus on what matters most: building robust, innovative software.
FAQs: AI Code Review
1) Can You Use AI to Do Code Reviews?
Absolutely. AI tools are specifically designed to perform code reviews. They analyze code for bugs, security risks, style violations, and performance issues. They integrate with development platforms like GitHub to provide automated feedback on pull requests, acting as a tireless assistant to the development team.
2) Is the AI Code Legit?
The suggestions and code generated by AI tools are generally "legit" in that they are syntactically correct and often follow best practices. However, the legality regarding intellectual property can be complex. You must review the terms of service for any AI tool and be mindful of its training data to avoid potential IP infringement.
3) Is AI Actually Good at Coding?
AI has become remarkably proficient at coding, particularly for well-defined tasks. It excels at generating boilerplate code, writing unit tests, and implementing standard algorithms. While it can produce entire applications, its strength currently lies in assisting human developers rather than replacing them. Its ability to improve existing code is a proven benefit.
4) Is AI Code Legal?
The legality of AI-written code is an evolving area of law. The primary concern is copyright and ownership. Code generated by an AI may be derivative of the data it was trained on, which can include open-source code with various licenses. Companies should consult with legal counsel to establish clear policies on the use of AI-generated code in proprietary projects.
5) What is the best free AI code review tool in 2025?
Free tools like Codacy and Codeant AI are popular in 2025. Codacy offers a free tier for open-source projects, while Codeant AI integrates directly into IDEs with real-time feedback.
6) What’s the difference between AI code review and automated code review?
AI code review uses machine learning and generative AI to analyze and suggest fixes. Automated code review refers to embedding these checks into CI/CD pipelines, so every commit or pull request is reviewed automatically.
7) Which AI code review tools integrate with GitHub?
GitHub Copilot now reviews pull requests, and third-party tools like Codacy and Snyk also integrate natively. These appear as comments on PRs, providing automated feedback.
8) How does AI code review compare to manual code review?
AI reviews are faster, more consistent, and scalable. Manual reviews excel at understanding business logic and project-specific goals. A hybrid approach is usually best.
9) Is AI code review safe for proprietary code?
Yes, but you must verify the tool’s privacy and compliance policies. Tools that process code locally or offer enterprise compliance features are safest for proprietary projects.
10) How do I set up automated AI code review in my CI/CD pipeline?
Choose a compatible tool (e.g., Codacy, Codeant AI).
Install its integration or GitHub/GitLab app.
Configure it to run on pull requests or commits.
Review feedback directly in your version control system.
Ready to ship cleaner code, faster?
Start with Dualite, free to begin, live in minutes.



