Return to All Blogs
Software Development Workflow: A Complete Guide
Discover the best software development workflows for 2025. Streamline your team's process and boost productivity.


A well-structured software development workflow is the backbone of any successful engineering team. It provides a clear, repeatable path from an initial idea to a production-ready application. This organized approach helps you build better products faster.
This article details the stages, components, and best practices for creating a powerful workflow. We will cover everything from project management and version control to automation and release management. You'll get actionable insights to improve your team's productivity and code quality.
What is a Software Development Workflow?
A software development workflow is the specific, repeatable pattern of activities that a team uses to design, build, test, and release software. It is the practical application of a software development lifecycle (SDLC) model.
This framework integrates directly with the broader development lifecycle. While the SDLC provides a high-level model (like Agile or Waterfall), the workflow details the specific tools, steps, and handoffs, such as how pull requests are reviewed or how code is pushed to production.
Key components of a typical workflow include:
Source Code Management: How code is stored, versioned, and merged.
Project Management: How tasks are defined, assigned, and tracked.
Automation Pipelines: The continuous integration and deployment systems.
Communication Protocols: The established channels for team interaction.
Continuous optimization is essential. A great workflow is never static; it is regularly reviewed and refined. According to Digital.ai's 17th State of Agile Report, 71% of companies use Agile in their software development lifecycle.
Stages of a Software Development Workflow
Understanding the distinct stages helps organize and manage the creation process from start to finish. Teams generally follow a comprehensive process that can be viewed through two different lenses: the full lifecycle and the core workflow.
7 Stages of Software Development Process
This represents the complete journey of a software product.
Conceptualization and planning: This initial stage involves brainstorming, market research, and feasibility analysi. Your team defines the project's goals, scope, and initial requirements, often formalizing them in documents such as Product Requirements Documents (PRDs) or use cases.
Design and prototyping: Architects and designers create the system's architecture and user interface (UI). They produce wireframes, mockups, and prototypes to validate the design concepts.
Development and coding: Developers write the actual code based on the design specifications. This is where the application's features and logic are built.
Testing: The quality assurance (QA) team rigorously tests the software for bugs, performance issues, and security vulnerabilities. This stage ensures the code meets quality standards. Deepen your approach with component testing, state transition testing, and a secure code review checklist.
Deployment: The finished code is released to the production environment, making it available to end-users. This can be a manual or automated process.
Maintenance: After release, the team provides ongoing support. This includes fixing bugs, updating systems, and ensuring the application runs smoothly.
Feedback and Iteration: The team gathers user feedback to inform future updates and improvements. This feedback loop drives the next cycle of development.
5 Stages of Workflow
This five-stage model describes the core development cycle. It's particularly well-suited for teams using Agile methodologies, like Scrum or Kanban, that operate in short, iterative cycles. This approach allows for frequent feedback and adaptation.
Planning: The team determines the work for the next cycle, often called a sprint. They select tasks from a product backlog and establish the objectives.
Design: For each task, the team outlines the technical solution and user interface. This might include creating technical specifications, wireframes, or user interface mockups.
Development: Programmers write the code for the planned features. This is the main construction phase where ideas are turned into functional software.
Testing: The new code is checked for correctness through automated tests and manual verification. This is frequently integrated into the development stage using continuous integration (CI) practices.
Deployment: After a feature is finished and verified, it's merged into the main codebase and released. With a continuous deployment (CD) model, this step occurs automatically after successful testing.
Key Elements of an Effective Workflow
An effective software development workflow is built on a foundation of strong project management, rigorous version control, agile methodologies, and clear communication. These elements work together to create a predictable and efficient process.
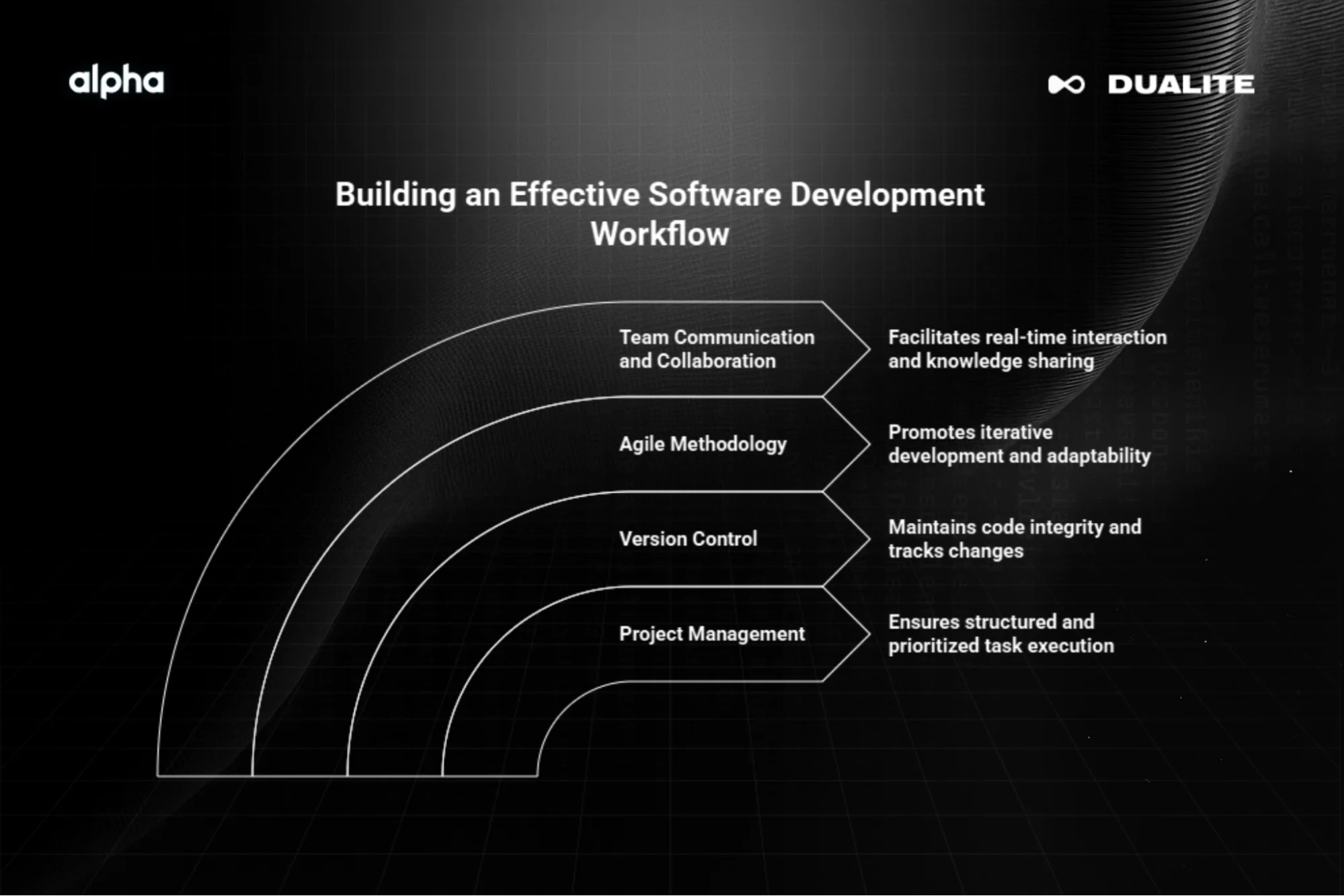
1) Project Management
Effective project management provides the structure for your team's work. It ensures everyone knows what to work on, what the priorities are, and when tasks are due.
You can manage projects with collaborative tools like Jira and Trello. These platforms allow you to create task boards, visualize progress, and manage backlogs, making the entire process transparent.
Task prioritization and tracking are fundamental. By focusing on the most important work first, you deliver value to users faster. Tracking progress helps identify bottlenecks before they derail your schedule.
The project manager is central to the software development workflow. They facilitate planning sessions, remove obstacles for the development team, and communicate with stakeholders to keep everyone informed.
2) Version Control
Version control is essential for maintaining code integrity in a team environment. It acts as a safety net, allowing you to track changes and revert to previous versions if something goes wrong.
Using GitHub and Git is the industry standard for version control. Git is the underlying technology, while GitHub provides a cloud-based hosting service with powerful collaboration features.
Following best practices in branching, commits, and pull requests is vital. A consistent branching strategy, like GitFlow, prevents chaotic codebase merges. Atomic commits with clear messages make your code history understandable. Pull requests serve as a formal process for code review and discussion before merging.
Here is a simple example of a feature branch workflow:
Bash
# Create and switch to a new feature branch |
3) Agile Methodology
Agile development processes are iterative approaches that focus on collaboration and customer feedback. Instead of a single, long development cycle, Agile breaks work into small increments.
Scrum is a popular framework for implementing Agile. Work is organized into "sprints," which are short, time-boxed periods (usually 1–4 weeks). To maintain coordination and continuous improvement, teams conduct regular ceremonies such as daily stand-ups to sync on progress and sprint retrospectives to refine their process. Each sprint concludes with a demonstration of a potentially shippable increment of the product.
The benefits of Agile are significant. It allows a team to adapt to changing requirements quickly. According to a 2025 TechReport 71% of organizations now apply Agile approaches, citing increased speed to market and team productivity as primary advantages.
The core principles of Agile software development include:
Customer satisfaction through early and continuous delivery.
Welcoming changing requirements, even late in development.
Delivering working software frequently.
Daily collaboration between business people and developers.
Building projects around motivated individuals.
4) Team Communication and Collaboration
Effective communication is essential to a workflow, as misunderstandings lead to wasted effort and defects.
While tools like Slack can facilitate real-time team collaboration, managing the information flow is vital to prevent overload. To achieve this, it is useful to institute practices such as standardized channel naming conventions (e.g., #proj-alpha, #tech-discussion, #alerts-builds) to direct information appropriately. Encouraging asynchronous status updates—where individuals post their progress at set intervals instead of giving constant reports—also reduces interruptions.
Setting up collaborative documentation systems is also important. A central, accessible knowledge base prevents information silos and helps onboard new team members quickly.
Streamlining Software Development with Automation
Automation is a cornerstone of a modern software development workflow. By automating repetitive tasks, you free up developers to focus on creative problem-solving and reduce the risk of human error.
Continuous Integration (CI)
Continuous Integration (CI) is a practice where developers frequently merge their code changes into a central repository. After each merge, an automated build and test sequence is run.
CI is important in modern workflows because it helps detect integration bugs early. It ensures that the main codebase is always in a healthy, buildable state.
You can implement CI with key tools like Jenkins and GitHub Actions. These tools automate the process of building, testing, and validating code changes as soon as they are pushed.
A simple CI pipeline in a ci.yml file might look like this:
YAML
name: Node.js CI |
CI best practices include maintaining a single source repository, automating the build, and making the build self-testing. Every commit should trigger a build to ensure rapid feedback.
Testing Automation
Automating tests provides a safety net that allows your team to make changes confidently. It includes unit tests for individual components, integration tests for component interactions, and end-to-end tests that validate the entire application.
The benefits are immense. Automated testing catches regressions immediately, improves code quality, and accelerates the feedback loop for developers. Studies show that teams with high test automation coverage spend 50% less time fixing bugs in production.
Tools like Postman (for APIs) and containerization platforms like Docker help you implement testing automation. You can create consistent, isolated environments to run tests, eliminating the "it works on my machine" problem.
Setting up a test-driven development (TDD) workflow is a powerful practice. In TDD, you write a failing test before you write the production code to pass that test. This ensures that your code is testable by design.
Deployment Pipeline
A deployment pipeline is the automated manifestation of your release process. It is an extension of CI, known as continuous deployment (CD) or continuous delivery.
An overview of a CD pipeline involves a series of automated stages. A code change that passes all CI checks is automatically deployed to a staging environment for additional testing and then, if successful, to production.
Setting up a dependable pipeline ensures quick and secure releases. By automating deployments, you reduce the risk of manual errors and can release updates to users multiple times a day. For high-risk deployments, however, it is prudent to include a manual approval step. This provides a final check, balancing the speed of automation with the need for careful oversight.
Docker and Kubernetes are instrumental in automating deployments. Docker allows you to package your application into a portable container. Kubernetes orchestrates these containers, managing deployment, scaling, and operations automatically across a cluster of machines.
Code Quality and Collaboration
A workflow must have mechanisms to maintain high code quality and facilitate collaboration. These systems ensure the long-term health and maintainability of your codebase architecture.
Code Reviews
Code reviews are a critical practice for maintaining high code quality. A second pair of eyes can spot bugs, logical errors, or design flaws that the original author might have missed.
You can conduct code reviews using the built-in features of GitHub or GitLab. The pull request (or merge request) feature provides a dedicated forum for discussing and iterating on code before it is integrated.
To make code review a smooth process, keep pull requests small and focused on a single change. Provide constructive, non-confrontational feedback. Automate linting and style checks to focus human review time on logic and architecture.
Bug Tracking
Issue tracking is the systematic process of identifying, reporting, and resolving bugs. An effective bug tracking system provides a central database of all known issues, their status, and their priority.
Popular bug tracking tools include Jira, Trello, and GitHub Issues. These tools integrate well with the development process, allowing you to link issues directly to code commits and pull requests. For improved visibility, they can also be connected with communication platforms like Slack or email, ensuring teams receive timely notifications about new issues and status changes.
Best practices for issue tracking include creating clear, reproducible bug reports. It is useful to have standardized templates and labels to categorize issues by priority (e.g., critical, high, medium) and type (e.g., bug, feature, technical debt).
Documentation Standards
Clear documentation is crucial in the software development workflow. It helps team members understand the codebase, the system architecture, and the project's operational procedures.
Set up a collaborative documentation system like Confluence or a simple project Wiki. This creates a single source of truth that is accessible to everyone on the team, from developers to project managers.
Ensure your coding and technical documentation are always up-to-date. Documenting your code with comments is a start, but high-level architectural documents are also necessary. A good practice is to update documentation as part of the "definition of done" for any new feature. Learn more in code documentation best practices.
Release Management
Release management is the process of managing, planning, scheduling, and controlling a software build through different stages and environments. It ensures that every release is predictable and stable.
Release Management Workflow
A typical release management workflow includes several steps.
Preparation: This involves planning the release, finalizing the features to be included, and running all final tests.
Staging: The release candidate is deployed to a staging environment, which is a production-like replica. Here, it undergoes final validation and user acceptance testing (UAT).
Production: Once approved, the release is deployed to the production environment for all users.
Post-Release Monitoring: After deployment, continuously monitor the release in the production environment. This practice helps to quickly identify and address any issues. Using observability tools like Datadog or Sentry provides real-time insights into application performance and errors.
You should implement a versioned release system, such as Semantic Versioning (SemVer). This practice assigns a version number (e.g., MAJOR.MINOR.PATCH) to each release, clearly communicating the nature of the changes.
Key tools and practices for release management include automated deployment scripts, feature flags, and rollback plans. Feature flags allow you to deploy code to production but keep new features hidden until they are ready, decoupling deployment from release.
Top 10 Tools That Help Improve Software Development Workflow
The right tech stack can significantly improve your team's efficiency. These tools automate tasks, enhance collaboration, and provide critical insights into your development process.
Dualite: Automates repetitive frontend development tasks. It helps you synchronize code, validate components, and improve collaboration between designers and developers.
Jira: A powerful tool for project management and issue tracking. It helps you plan sprints, track progress on a kanban board, and generate reports on team velocity.
VS Code: A popular, lightweight integrated development environment (IDE). It offers a rich ecosystem of extensions for debugging, Git integration, and language support.
GitHub: The leading platform for version control and collaboration. It combines Git hosting with pull requests, issue tracking, and a CI/CD system (GitHub Actions).
Docker: A containerization platform for building and running applications in isolated environments. It ensures consistency from development to production.
Slack: A communication hub for real-time team collaboration. It integrates with hundreds of other development tools to bring notifications and alerts into one place.
Jenkins: An open-source automation server for continuous integration and continuous deployment. It is highly extensible and supports a vast number of plugins.
Embold: A static code analysis platform that provides deep insights into code health. It helps you find bugs, security vulnerabilities, and design issues before they reach production.
Postman: An API platform for building and using APIs. It helps you design, test, and document your APIs, which is essential for a microservices architecture.
GitLab: An all-in-one DevOps platform. It combines source code management, CI/CD, security scanning, and project management in a single application.
This selection of tools addresses every part of the software development workflow, from planning to deployment.
10 Best Practices for Optimizing Your Development Workflow
Optimizing your workflow is an ongoing activity. By adopting proven best practices, you can create a more efficient, predictable, and enjoyable development environment. Here are ten practices to streamline your process.
Standardize Your Environments: Use tools like Docker to ensure development, staging, and production environments are as similar as possible.
Automate Everything Repetitive: Automate your builds, tests, and deployments to reduce manual work and errors.
Keep a Lean Backlog: Regularly groom your product backlog to remove outdated items and ensure priorities are clear.
Implement Small, Frequent Releases: Releasing in small batches reduces risk and gets feedback from users faster.
Use Feature Flags: Decouple code deployment from feature release. This lets you test in production safely.
Prioritize the Developer Experience (DevEx): Invest in fast machines, good tools, and streamlined processes. A happy developer is a productive developer.
Conduct Blameless Postmortems: When an incident occurs, focus on identifying process flaws, not blaming individuals.
Invest in Asynchronous Communication: Document decisions and discussions to reduce the need for meetings and respect focus time.
Secure Your Supply Chain: Use automated tools to scan dependencies for vulnerabilities. A secure software development workflow is non-negotiable.
Establish a Clear Git Branching Strategy: A strategy like GitFlow or GitHub Flow brings order to your codebase.
Continuous feedback loops and retrospectives are essential. At the end of each sprint or project, your team should discuss what went well and what could be improved. This institutionalizes the practice of continuous improvement.
Pair programming, pull requests, and automated testing are powerful techniques. Pair programming improves code quality and shares knowledge. Pull requests formalize the review process. Automated tests provide the confidence to refactor and iterate quickly.
Optimizing Your Workflow Using Git and CI/CD
You can manage your Git workflow efficiently by using a clear branching model and writing descriptive commit messages. These simple disciplines make your project history easy to follow.
Setting up a CI/CD pipeline creates a smooth transition from code commit to production. It acts as a quality gate, ensuring that only tested, high-quality code reaches your users. A good pipeline is the backbone of an effective software development workflow.
Conclusion
A solid software development workflow is not a luxury; it is a necessity for any modern engineering team. It provides the structure needed to build high-quality software consistently and at scale. It transforms a chaotic process into a predictable, efficient system.
We encourage you and your team to implement these practices. Start small by automating one part of your testing suite or standardizing your code review process. Each improvement contributes to better productivity and superior code quality.
The methods for building software are constantly being refined. By committing to continuous optimization and embracing automation, your team will be well-equipped to create outstanding products now and in the future.
FAQs
1) What is the software development workflow?
A software development workflow refers to the series of processes, tools, and practices that a development team follows from the planning stage to the final deployment and maintenance of a software application.
2) What are the 7 stages of the software development process?
Conceptualization and planning
Design and prototyping
Development and coding
Testing
Deployment
Maintenance
Feedback and Iteration
3) What are the 5 stages of workflow?
Planning
Design
Development
Testing
Deployment
4) What are the 5 steps of the software development process?
Requirement gathering
Design
Implementation
Testing
Maintenance



